


SAR-based flood mapping is a standard and reliable method for determining the extent of major floods. SAR can penetrate cloud-cover, operate in any weather conditions and provide timely and crucial information about one of the most frequent and devastating natural disasters: flooding. Too often limited technical know-how separates the disaster community from the information they need; this Recommended Practice provides a near real-time, cloud-based and easy-to-use method for flood extent mapping, designed to overcome technical limitations.
Without the need for downloading large and complex data, this cloud-based Recommended Practice completes all analysis without taking up hard drive space or processing power of the end-users’ device. By inputting the provided code and simply outlying the region of interest as well as the before and after dates, this methodology produces in seconds what a GIS user may take hours to complete.
As one of the most common natural disasters, flooding affects nearly every place on the globe. In addition to the 100 people who lose their lives, flooding destroys $8 billion annually, creating major problems for both first responders and disaster managers to address after a disaster strikes. This Recommended Practice not only creates a quick and usefully outline of floods but overlays that with land use and population information to instantly output statistics such as area of cropland and number of population within the damage areas.
Requirements
- A Google Earth Engine account is required to use this code. A link is provided in the step-by-step section of this Recommended Practice. Please Note: The account may require a few days to be active.
- Some storage left on Google Drive (20 MB- 1GB, depending on the size of the study area)
- Unlike software-based Recommended Practices, this cloud-based solution has very little hardware requirements as no processing is done on the user’s computer.
- A stable internet connection is required as the processing is done on a cloud-based platform and the results are run through Google Earth Engine’s own JavaScript code.
Applications
This Recommended Practice can be used for any large areas with major flooding. The results are scalable, and the area of interest and dates are free for the user to determine. The code pulls data from the Copernicus Programme’s Sentinel-1 satellite and therefore is not able to provide information for any floods before the satellite's launch in July 2014.
Strengths and Limitations
Strengths
- The workflow can be easily applied to different areas
- Fully automatically, after specifying the area of interest and time periods
- Very little processing time
- Near-real time monitoring of flood events globally
- Cloud independent flood monitoring
- Cloud-processing allows the use of auxiliary datasets to delineate the flood extent (e.g. slope)
- Provides additional information on exposed population, affected cropland & urban areas
Limitations
- False positives from changes on the land surface, not caused by flooding
- Difficulties of detecting flood in urban or densely vegetated areas
- No capturing of flood peak due to the acquisition frequency of Sentinel-1
- False positives caused by differences in relative orbits
- Border noise errors (when processing large areas)
- Spatial resolution of MODIS Land Cover (500 m) and JRC GHSL Population (250 m) causes uncertainties for the damage assessment
For more detailed information, see ‘Limitations’ section in the step-by-step tutorial.
Objective
This Recommended Practice aims to be a simple and quick tool for users of any experience level to create information about flooding. The code is to be input into Google Earth Engine and run according to the area and dates specified by the user. After the process has run, the code will create a delineation of flood extent using SAR data and change detection methodology. The code will also produce information about cropland, urban areas and population density exposed. The code can be run with little-to-no user knowledge of GIS or coding; the code provided has a description of each tool it uses to create the end information, as well as an overview of the strengths and limitations of the product. Additionally, this Recommended Practice can also serve as a base code for more experienced users to alter and create a better tool for their individual disaster needs.
Disaster type: Flood
Disaster Cycle Phase:
- Recovery & Reconstruction
- Relief & Response
Test Site
Beira, Province of Sofala, Mozambique
Context
On 14 March 2019 Cyclone Idai made landfall in Mozambique. The storm caused massive flooding across wide stretches of the country. By 28 March 468 people had died from the disaster and an additional 136,000 were displaced. Worries grew as, in addition to major population centers, the central states – which produce roughly half of the country’s food – were heavily affected. Both lives and crops were lost, and disaster managers were facing tough problems on how best to confront rescue and response across the region. In this context, quick and accessible information is critical for the disaster community to build a comprehensive plan on how to respond rapidly so that more communities, crops and lives aren’t lost as the country works to rebuild. This Recommended Practice is built to be used as a tool to provide that information.
Applicability
This tool can be used to provide a comprehensive overview of a flood, across any size area of interest – from small communities to states. In addition to the outline of flood areas, this code produces information about farmland affected to better plan for food security concerns after a disaster. Additionally, data about major population centres are highlighted by this tool, providing information to be used by rescue and response operations; however there as this methodology is meant for broad information provision in a global context, there are inherent uncertainties in this methodology which are discussed further in this Recommended Practice, it is important that this tool not be used as the only source of information for rescue response planning.
This tool is built to provide instant and near real-time information about flood extent, as well as cropland and urban areas affected. It can be used in any areas affected by floods globally. It works independently of weather and can be used with little-to-no GIS or coding experience.
Data Access
The aim of this step-by-step procedure is the generation of a flood extent map for the assessment of affected areas. The flood extent is created using a change detection approach on Sentinel-1 (SAR) data. To assess the number of potentially exposed people, affected cropland and urban areas, additional datasets will be intersected with the derived flood extent layer and visualized.
The following step-by-step procedure uses Google Earth Engine, which is a powerful web-platform for cloud-based processing of remote sensing data on large scales. The advantage mainly lies in its computational speed, as processing is outsourced to Google’s servers. The platform provides a variety of constantly updated datasets which can be accessed directly within the code editor. No download of raw imagery is required. While it is free of charge, an activate Google account with Google Earth Engine is required. A confirmation usually comes within 2-3 work days. For a quick orientation around the code editor, click here: https://earthengine.google.com/platform/.
The code for this Recommended Practice can be imported by following this link
https://code.earthengine.google.com/f5c2f984c053c8ea574bfcd4040d084e.

There you will find detailed comments along with the code line-by-line. Alternatively, you can create a new file in the code editor, download this script and paste it.

Data Preparation/Pre-processing
Step 1: Study area selection
In the following section we will present three different ways to specify the location of your study area. This information is necessary to limit the processing extent of the analysis and avoids redundant calculations. Users can draw an area of interest by hand, upload location information from a file or import country boundaries provided as GEE FeatureCollection.
1.1: Hand-drawn polygons
Boundaries can be created interactively. This is the quickest and easiest option, suitable for exploring and testing the script in different regions. The polygon tool can be activated in the top-right corner of the map pane. Vertices are created with left clicks and the polygon is completed by double-clicking. A geometry can consist of more than one polygon. Press 'Exit' once you are done setting up your study area. The geometry will be listed under 'Imports' at the top of the script.
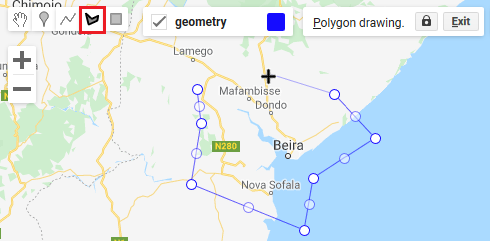

1.2: Shapefile
Defining the spatial processing extent with a Shapefile (.shp) is the most accurate solution. This is recommended when researching a very distinct study area (e.g. a watershed). Start the import via the 'Assets'-tab in the top left corner. On the 'New' drop-down menu select 'Table upload', then select your file. Careful: Make sure also to include the .dbf and .shx files, as the shapefile relies on them.

Uploading files usually takes a few minutes. You can observe the progress in the 'Tasks’ tab on the top right. Once the 'Asset ingestion' task is completed (turns blue) you can import the shape to the script. Under 'Assets' click the 'Import' button so the table is listed in the imports section. For the script to recognize this new table, rename it to 'geometry'.

1.3 In-build country boundary features
GEE so far provides a very limited amount of shapes, such as major administrative boundaries. If one seeks to perform this analysis on country level though, there is a suitable data set provided that contains simplified features. In GEE, search for 'LSIB' or 'International Boundaries'. The FeatureCollection can be imported using its ID ('USDOS/LSIB_SIMPLE/2017'). Select a specific country by filtering the collection by FIPS country code. Here is an example for Mozambique ('MZ'):
var geometry = ee.FeatureCollection('USDOS/LSIB_SIMPLE/2017').filterMetadata('country_co', 'equals', 'MZ');
Paste these lines of code at the top of your script and make sure this is the only geometry variable in the script. Replace 'MZ' with a country code of your choice.
Step 2: Time frame & sensor parameters selection
Besides the area of interest, the user is required to define pre- and post-flood time periods in the first few lines of the code. By setting periods, not single dates, the user allows the selection of enough tiles to cover the area of interest. Sentinel-1 imagery is acquired minimum every 12 days for each point on the globe (Figure 6).

Furthermore, the user can choose between ‘HV’ and ‘VV’ polarization to perform the analysis. ‘HV’ is widely suggested for flood mapping, since it is more sensitive to changes on the land surface, while ‘VV’ is rather susceptible to vertical structures and might be useful to delineate open water from land surface (e.g. shoreline detection or a large water body that occurred after a flood event).
Fig. 7: Google Earth Engine Script for polarization
When performing change detection, it is necessary to select the same pass direction for the images being compared to avoid false positive signals caused by differences of the viewing angle. The user might choose between ‘DESCENDING’ and ‘ASCENDING’ pass direction, depending on the study area. As shown in Figure 9 some areas are only covered by descending pass directions (e.g. Brazil) or only by ascending (e.g. Namibia). Other areas, such as Mozambique or entire Europe are covered by both.


To check whether the area of interest is covered given the selected parameters, expand ‘Layers’ in the top-right corner of the map viewer and select ‘After Flood’ as well as ‘Before Flood’.
Change the parameters ‘time frame’ and ‘pass_direction’ if your area of interest is not entirely covered!

Step 3: Run the script
When all parameters are selected hit ‘Run’ and wait for a few minutes until your results are displayed.

Step 4: Visualize results in GEE
Select the full-screen button in the top-right corner of the map viewer to visualize the flood product. Within ‘Layers’ you can check or uncheck the layers you are interested in and take a screenshot of the map as a first overview.

Step 5: Export products
To export the generated products into your Google Drive account, click on ‘Tasks’ in the top-right corner of the code editor and hit ‘RUN’, and choose where to save the file. ‘Flood_extent_raster’ outputs a GeoTiff raster file of the flood extent. ‘Flood_extent_vector’ is a shapefile, where the flood extent has already been converted to polygons, which might be useful for further analysis. ‘Exposed_population’ includes a raster layer, showing the location and number of potentially exposed people.
Processing Steps:
This section explains the processing steps, which are performed automatically when running the Google Earth Engine script. It is recommended to read through them in order to understand how the data is being processed, which auxiliary datasets are used and what limitations the analysis may have for individual cases.
Step 6: Data filtering
According to the predefined parameters the entire Sentinel-1 GRD archive, called ImageCollection in Google Earth Engine, is filtered by the instrument mode, the polarization, pass direction, spatial resolution and are clipped to the boundaries of the area of interest. The filtered ImageCollection is then reduced to the selected time periods (before and after the flood event).
Step 7: Preprocessing
Information from Sentinel-1 Level-1 Ground Range Detected (GRD) imagery in Google Earth Engine has already undergone the following preprocessing steps:
- Apply-orbit-file (updates orbit metadata)
- ARD border noise removal (removes low intensity noise and invalid data on the scene edges)
- Thermal noise removal (removes additive noise in sub-swaths)
- Radiometric calibration (computes backscatter intensity using sensor calibration parameters)
- Terrain-correction (orthorectification)
- Conversion of the backscatter coefficient (σ°) into decibels (dB)
Hence, the code in this Recommended Practice only applies a smoothing filter to reduce the inherent speckle-effect of radar imagery (Fig. 13).

Step 8: Change detection
This script uses a simple, straight-forward change detection approach, where the after-flood mosaic is divided by the before-flood mosaic, resulting in a raster layer showing the degree of change per pixel. High values (bright pixels) indicate high change, low values (dark pixels) point toward little change. The predefined threshold of 1.25 is applied assigning 1 to all values greater than 1.25 and 0 to all values less than 1.25. The binary raster layer created by this process shows the potential flood extent (Fig. 14). The threshold of 1.25 has been selected through trial and error and might be adjusted in case of high rates of false positive or false negative values.

Step 9: Refining the flood extent layer
Several additional datasets are used to eliminate false positives within the flood extent layer. The JRC Global Surface Water dataset is used to mask out all areas covered by water for more than 10 months per year. The dataset has a resolution of 30 m and was last updated in 2018.
To remove areas with over 5 % slope, a digital elevation model (WWF HydroSHEDS) has been chosen, which is based on SRTM data, and has a spatial resolution of 3 arc-seconds. Furthermore, the connectivity of the flood pixels is assessed to eliminate those connected to eight or fewer neighbors. This operation reduces the noise of the flood extent product (Fig. 15).

Assessment:
Step 10: Area calculation of flood extent
To compute the area of the flood extent, a new raster layer is created calculating the area in m2 for each pixel, taking the projection into account. By summing up all pixels, the area information is derived and converted into hectares. The result is displayed on the ‘Results’ panel in the bottom-left corner of the Map Viewer.
Step 11: Exposed population density
To estimate the number of exposed people, the code uses the JRC Global Human Settlement Population Layer, which has a resolution of 250 m, and was last updated in 2015. It contains information on the number of people living in each cell. To intersect the flood layer with the population layer, the flood extent raster first needs to be reprojected to the resolution and projection of the population dataset. Subsequently, an intersection between both layers is computed and displayed as a new raster layer (Fig. 16 right). To calculate the number of exposed people, all pixel values of the exposed population raster are summed up and displayed in the ‘Results’ panel on the Map Viewer.

Step 12: Affected cropland
To estimate the amount of affected cropland, the MODIS Land Cover Type product has been chosen. The dataset has a spatial resolution of 500 m and is updated yearly. It is the only global dataset on Land Cover currently available in Google Earth Engine. The Land Cover Type 1 band consists of 17 classes with two cropland classes (class 12: at least 60% of area is cultivated and class 14: Cropland/ Natural Vegetation Mosaics: small-scale cultivation 40-60% with natural tree, shrub, or herbaceous vegetation). Both classes are extracted from the dataset and intersected with the flood extent layer, which has been resampled to the scale and projection of the MODIS layer (Fig. 17).
The area of the affected cropland is calculated the same way as for the flood extent and displayed in the ‘Results’ panel.

Step 13: Affected urban areas
Affected urban areas are calculated the same way as the previous two steps, using the MODIS Land Cover Type dataset. The ‘Urban Class 13’ of the band ‘Land Cover Type 1’ is extracted to assess potentially affected urban areas. In this process, affected urban areas are very likely to be underestimated, due to the difficulties of detecting water in build-up areas. See Strengths and Limitations for further details.